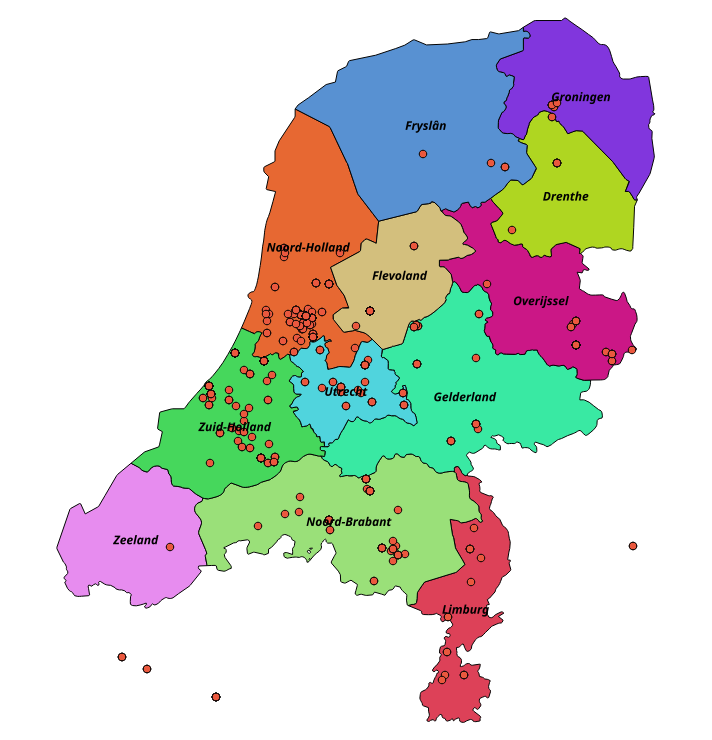
A few weeks ago one of my web archiving colleagues approached me with an interesting question. From a list of Dutch web domains, he wanted to identify the (Dutch) province in which each domain is hosted. He was particularly interested in domains hosted in the province of Friesland. After some experimentation I was able to answer this question using a two-step procedure:
Geo-locate the web domains using a custom Python script.
Combine the results of the geolocation exercise with openly available geographical data using QGIS, an open-source geographical information system (GIS).
Even though the outcome of the analysis is not particularly interesting, I imagine both the geolocation methodology and the GIS analysis steps might be useful to others. So, this blog post is primarily intended as a tutorial that gives a walkthrough of the steps I followed.
Earlier this year I published this blog post on the recovery of data from ’90s data tapes. I will give a presentation on this during the upcoming iPres 2019 conference, and wrote a paper that discusses this work in more detail than my earlier blog post. The original paper (in PDF format) can be found here. The paper references a wealth of useful resources, but some of these are not easily accessible because the LaTeX template used does not handle hyperlinks well (this will be fixed in the final, post-conference version of the paper). Because of this I’ve created a web-friendly version of the paper below.
SATA hard disk, USB Flash drive and 3.5" floppy disks
As I explained in the introduction of this earlier blog post, as part of our ongoing web archaeology project we are currently developing workflows for reading data from a variety of physical carrier formats. After the earlier work on data tapes and optical media, the next job was to image a small box with 3.5” floppy disks. Easy enough, and my first thought was to fire up Guymager and be done with it. This turned out to be less straightforward than expected, which led to the development of yet another workflow tool: diskimgr. In the remainder of this post I will first show the issues I ran into with Guymager, and then demonstrate how these issues are remedied by diskimgr.
In 2015 I wrote a blog post on preserving optical media from the command-line. Among other things, it suggested a rudimentary workflow for imaging CD-ROMs and DVDs using the readom and ddrescue tools. Even though we now have a highly automated workflow in place for bulk processing optical media from our deposit collection, readom and ddrescue still prove to be useful for various special cases that don’t quite fit into this workflow. The materials that we are currently receiving as part of our web archaeology activities are a good example. These are typically small sets of recordable CD-ROMs that are often quite old, and such discs are highly likely to be in less than perfect condition. For these cases a highly automated, iromlab-like workflow is unnecessary, and to some degree even impractical. Nevertheless, it would be useful to have some degree of automation, especially for things like the addition and packaging of associated metadata. This prompted the development of the omimgr workflow tool. In the the remainder of this blog post I will give an overview of omimgr.
When the KB web archive was launched in 2007, many sites from the “early” Dutch web had already gone offline. As a result, the time period between (roughly) 1992 and 2000 is seriously under-represented in our web archive. To improve the coverage of web sites from this historically important era, we are now looking into Web Archaeology tools and methods. Over the last year our web archiving team has reached out to creators of “early” Dutch web sites that are no longer online. It’s not uncommon to find that these creators still have boxes of offline carriers with the original source data of those sites. Using these data, we would (in many cases) be able to reconstruct the sites, similarly to how we reconstructed the first Dutch web index last year. Once reconstructed, they could then be ingested into our web archive.