Earlier this year I wrote a blog post about geo-locating web domains, and the subsequent analysis of the resulting data in QGIS. At the time, this work was meant as a proof of concept, and I had only tried it out on a small set of test data. We have now applied this methodology to the whole of the Dutch (.nl) web domain, and this follow-up post presents the results of this exercise.
In 2019, Dutch telecommunications company KPN announced its plans to phase out its subsidiary XS4ALL, which is one of the oldest internet service providers in the Netherlands. With this decision, thousands of homepages and personal web sites that are hosted under the XS4ALL domain are at risk of disappearing forever. The web archiving team of the National Library of the Netherlands (KB) has started an initiative to rescue a selection of these homepages, which includes some of the oldest born-digital publications of the Dutch web. This blog post describes an attempt to rescue and restore one of the oldest and most unique homepages from this collection: Liesbet’s Virtual Home (Liesbet’s Atelier), the personal web site of Dutch Internet pioneer Liesbet Zikkenheimer, which has a history that goes back to 1995. First I give some background information about XS4ALL, and the KB-led rescue initiative. Then I move on to the various (mostly technical) aspects of restoring Liesbet’s Virtual Home. Finally, I address the challenges of capturing the restored site to an ingest-ready WARC file.
According to its authors, “the ISO/IEC TS 22424 series supports long-term preservation of EPUB publications via a dual strategy”. The standard is made up of 2 parts, which are sold as separate documents on the ISO website:
In this blog post I will take a closer look at both parts of the standard. What do they purport, what is their scope, and to what degree do they live up to their stated promises? Readers who are only interested in the most important findings may want to jump to the “Summary and discussion” section at the end of this post.
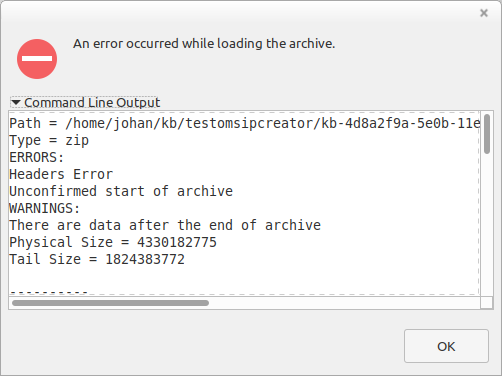
We recently started using Microsoft OneDrive at work. The other day a colleague used OneDrive to share a folder with a large number of ISO images with me. Since I wanted to work with these files on my Linux machine at home, and no official OneDrive client for Linux exists a this point, I used OneDrive’s web client to download the contents of the folder. Doing so resulted in a 6 GB ZIP archive. When I tried to extract this ZIP file with my operating system’s (Linux Mint 19.3 MATE) archive manager, this resulted in an error dialog, saying that “An error occurred while loading the archive”:
The output from the underlying extraction tool (7-zip) reported a “Headers Error”, with an “Unconfirmed start of archive”. It also reported a warning that “There are data after the end of archive”. No actual data were extracted whatsoever. This all looked a bit worrying, so I decided to have a more in-depth look at this problem.
Following earlier work on the preservation of optical media and data tapes, I recently got a request to make an inventory of offline digital data carriers in the KB’s deposit collection. The goal was to obtain approximate figures on the various carrier types in the collection. This was partially prompted by a project on at-risk digital heritage on physical carriers by the Dutch Digital Heritage Network (NDE) that the KB is participating in. This blog post presents the results.







{kind=link}
{kind=link}
{kind=link}