
PDF Quality assessment for digitisation batches with Python, PyMuPDF and Pillow

This post introduces Pdfquad, a software tool that for automated quality assessment for large digitisation batches. The software was developed specifically for the Digital Library for Dutch Literature (DBNL), but it might be adaptable to other users and organisations as well.
Context of this work
The Digital Library for Dutch Literature (DBNL) is a collection of literary texts from the Dutch language area. It is a collaboration between the Dutch Language Union, the Flanders Heritage Libraries and the KB. As part of its mission, DBNL digitises books and periodicals, which are then made available on its website.
Most of the digitisation work is contracted out to external suppliers. Unlike most of the KB’s digitised collections, the DBNL material is scanned to PDF format. For each publication, two versions are created:
- A production master PDF, which serves as the source material for several derived products (PDF and EPUB versions with high quality, manually transcribed text).
- A (relatively) small access PDF with the scanned pages, which is made available on the DBNL website.
Here’s an example publication. Note the “Downloads” section, which contains links to the access PDFs and EPUB.
PDF requirements
The scanned PDFs need to conform to requirements that are defined in a technical specifications document, which has been updated last year. It covers both aspects related to capture quality, as well as technical characteristics of the PDF. The latter category includes things like:
- Scanned pages must be encoded using JPEG compression, using 85% quality for the production master, and 50% quality for the access file.
- Pages must be scanned in full-colour, with a colour space that is defined by an embedded ICC profile.
- Encryption and any other access restrictions are not allowed.
- Digital signatures and watermarks are not allowed.
- Any content besides the scans is not allowed (no layers or active content).
- The PDF must not open with thumbnails.
Thus far, conformance to such technical aspects was mostly tested manually on a sample basis, using a variety of software tools. This situation is not ideal, especially given the fact that the PDFs are delivered as part of huge production batches. At the request of our Digitisation department, I looked into a way to do these quality checks in a more systematic and scalable manner. This has resulted in the Pdfquad software. The name is an acronym for “PDF QUality Assessment for Digitisation batches”. It can be used to automatically assess PDF documents in a digitisation batch against one or more sets of user-defined technical requirements.
General concept
The general idea behind Pdfquad isn’t entirely new. In 2013 I wrote the Jprofile tool, which does automated quality checks on batches of JP2 (JPEG 2000 Part 1) images. Jprofile uses Jpylyzer to extract technical characteristics of a JP2 file, and then evaluates these characteristics against a set of technical requirements that are encoded as Schematron rules. This software was used for several years operationally by our digitisation department1.
Even though Jprofile was designed for a different file format, the overall concept is equally usable for batches with PDFs. So, I took the old Jprofile code as a starting point, removed all JPEG 2000 specific code, adapted it to our PDF case, and made it quite a bit more flexible in the process.
Pdfquad overview
The following figure gives a general overview of how Pdfquad works:
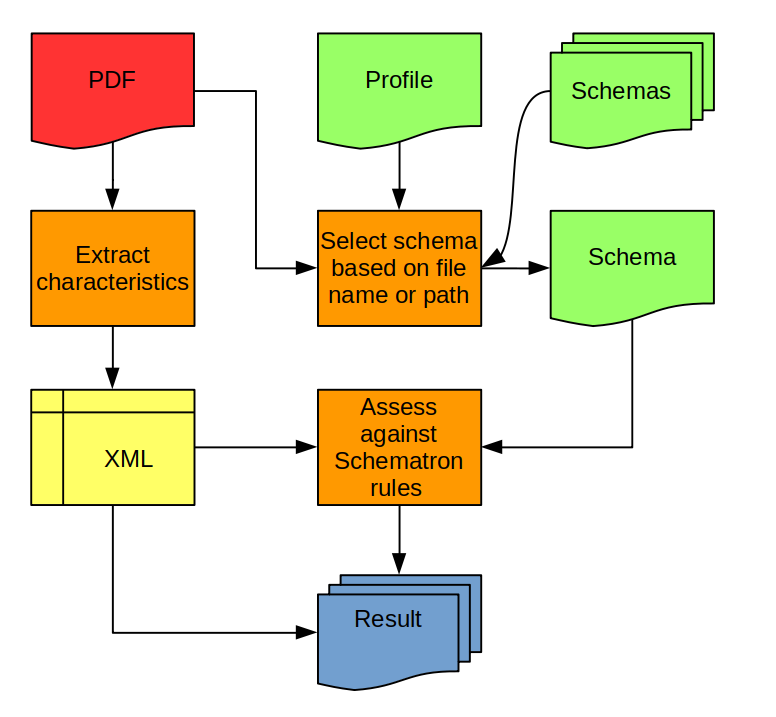
For each PDF in a batch, it extracts the relevant technical characteristics, which are serialized as XML. This XML is then assessed against a set of Schematron rules, which represent the requirements. There may be different schemas (e.g. for production masters and access PDFs). A profile defines which schema must be used for a specific PDF, based on its file name or the name of its direct parent directory. Finally, the results of both the feature extraction and the Schematron assessment are written to a set of output files. In the following sections I will describe these components in more detail.
PDF characteristics vs image characteristics
Some of the DBNL PDF requirements reflect technical characteristics at the PDF document level (e.g. the presence of encryption), whwereas aspects like JPEG quality must be evaluated at the level of the image stream. In most cases, an image in PDF is implemented as an Image XObject. This is a PDF dictionary with various key-value pairs that describe the image properties, followed by the image stream. In our case, we expect the image stream to contain data in JPEG format. This means we cannot just use any PDF feature extraction tool (e.g. VeraPDF), as such tools are unable to provide the necessary information at the image stream level.
Feature extraction with PyMuPDF and Pillow
As a solution to this, Pdfquad uses the PyMuPDF library to parse the PDF. PyMuPDF is also used to extract all relevant PDF-level characteristics. For each image, it then passes the image stream data to the Python Imaging Library (Pillow), which is used to extract the image-level characteristics. With this combination of PyMuPDF and Pillow, I was able to extract all information that is needed to verify all but one of our PDF requirements. The exception here was JPEG quality, which doesn’t immediately follow from Pillow’s output. However, Pillow can report the quantization tables of a JPEG image, and these can be used to estimate JPEG quality. My earlier post on JPEG quality estimation covers this in detail, and presents a least-squares matching method that is also used in Pdfquad.
Feature extraction walkthrough
It’s worth pointing out that Pdfquad’s feature extraction is currently limited to those characteristics that are needed to verify the DBNL requirements. However, extending the extraction to additional characteristics would be pretty straightforward. Readers who are interested in this (or in feature extraction with PyMuPDF and Pillow in general) might want to check out Pdfquad’s properties module. Here’s a brief walkthrough:
- The getProperties function parses a PDF document, extracts some document-level characteristics and then iterates over all pages.
- The getPageProperties function extracts all page-level characteristics, and iterates over all images on a page.
- The getImageProperties function process an image object, and calls two functions that extract the dictionary-level and stream-level characteristics, respectively.
- The getImageDictProperties function extracts all characteristics at the image dictionary level.
- The getImageStreamProperties function extracts all characteristics at the image stream level, using Pillow.
The feature extraction code also keeps track of any exceptions that may occur during parsing. These usually indicate a problem with the PDF, and the DBNL Schematron includes rules that verify their absence.
Profiles and schemas
Pdfquad needs to understand the structure of a digitisation batch, and how the PDFs inside it must be evaluated. As an example, let’s assume we have the following batch structure:
└── 20241105
└── _boe012192401
├── 300dpi-50
│ └── _boe012192401_01.pdf
└── 300dpi-85
└── _boe012192401_01.pdf
Here we have a directory tree where each “300dpi-85” directory contains a high-quality production master PDF, and each “300dpi-50” directory an access PDF. In order to analyse this batch structure, Pdfquad needs to know two things:
- A file or directory name pattern that differentiates between production master and access PDFs.
- A reference to the Schematron file that is used to evaluate both.
Both are defined in an XML-formatted profile, which Pdfquad expects as a command-line argument. Here’s an example:
<?xml version="1.0"?>
<profile>
<schema type="parentDirName" match="endswith" pattern="pi-85">pdf-dbnl-85.sch</schema>
<schema type="parentDirName" match="endswith" pattern="pi-50">pdf-dbnl-50.sch</schema>
</profile>
Here, the profile contains two schema elements, which represent the production master and access PDF, respectively. Each element refers to a corresponding Schematron file. In this case, the values of the “type”, “match” and “pattern” “attributes in the first element tell Pdfquad that if the name of a PDF’s direct parent directory ends with “pi-85”, it must use Schematron file “pdf-dbnl-85.sch”.
This file, which can be viewed here, contains the Schematron rules that are used to evaluate the extracted characteristics.
Although the profile and Schemas that are part of the current Pdfquad release are specific to the DBNL case, it is possible to use the software with custom profiles and schemas. This could extend its applicability to other PDF-based digitisation workflows and batch structures.
Output
For each batch, Pdfquad produces two types of output:
- A comma-delimited summary file. This lists, for each PDF, whether the Schematron assessment completed without errors, the outcome of the Schematron assessment, the number of pages, and a reference to the comprehensive output file (see below).
- One or more comprehensive output files in XML format. These contain all extracted properties, as well a the Schematron report and the assessment status. Here’s an example.
The comprehensive output can get really large. Because of this, Pdfquad splits the results across multiple output files, using the following naming convention (the actual file prefixes can be defined as a command-line option):
- pq_mybatch_001.xml
- pq_mybatch_002.xml
- etcetera
By default, Pdfquad limits the number of reported PDFs for each output file to 10, after which it creates a new file. There’s a command-line option to change this behaviour.
Final thoughts
Pdfquad is still in early development, and the current feature extraction component in particular is limited to the specific needs of our DBNL digitisation workflow. However, I would expect that the software might be useful for others as well. The profile and schema definitions offer a lot of flexibility for different batch structures, without any changes to the code. This was a deliberate design choice, as we may use the software for PDFs from some other digitisation projects in the future. Meanwhile, the feature extraction module could be extended quite easily to include additional characteristics.
On a different note, I was pleasantly surprised by PyMuPDF. I had never worked with it before (or any other Python PDF library for that matter), but using it turned out to be unexpectedly straighforward. I will definitely return to it for future PDF-related work, and other PDF/Python heads should probably check it out.
Link to Pdfquad
Pdfquad and its documentation can be found here:
PDF QUality Assessment for Digitisation batches
-
It has since been repaced by third-party software with the same functionality (which also uses Jpylyzer) ↩
-
PDF
- PDF Quality assessment for digitisation batches with Python, PyMuPDF and Pillow
- Escape from the phantom of the PDF
- VeraPDF parse status as a proxy for PDF rendering: experiments with the Synthetic PDF Testset
- Identification of PDF preservation risks with VeraPDF and JHOVE
- On The Significant Properties of Spreadsheets
- PDF processing and analysis with open-source tools
- Policy-based assessment with VeraPDF - a first impression
- PDF/A as a preferred, sustainable format for spreadsheets?
- Why PDF/A validation matters, even if you don't have PDF/A - Part 2
- Why PDF/A validation matters, even if you don't have PDF/A
- When (not) to migrate a PDF to PDF/A
- Identification of PDF preservation risks: analysis of Govdocs selected corpus
- Identification of PDF preservation risks with Apache Preflight: the sequel
- What do we mean by "embedded" files in PDF?
- Identification of PDF preservation risks with Apache Preflight: a first impression
- PDF – Inventory of long-term preservation risks
-
schematron
- PDF Quality assessment for digitisation batches with Python, PyMuPDF and Pillow
- Policy-based assessment with VeraPDF - a first impression
- Why PDF/A validation matters, even if you don't have PDF/A - Part 2
- Policy-based assessment of EPUB with Epubcheck
- Automated assessment of JP2 against a technical profile

{kind=link}
Comments