
How to save a web page to the Internet Archive
This short tutorial shows how to take a snapshot of a web page, and save it to the Internet Archive’s Wayback Machine.
Method 1: web interface
- Go to the Wayback website: https://archive.org/web/
- Paste the URL of the page you want to archive into the Save Page Now box (at the bottom-right).
- Click on the Save Page button (or press enter).
- Wait while the page is being crawled. Once the archiving process is complete, the URL of the archived page appears.
Method 2: bookmarklet
This method is faster than using the web interface, but you will first need to install a bookmarklet (which is just a browser bookmark that contains some JavaScript).
Installation
-
Go to the Save Page to Wayback Machine Bookmarklet link here: http://marklets.com/Save%20Page%20to%20Wayback%20Machine.aspx
-
Click at the left-hand site of the URL bar, and drag it to the bookmarks toolbar of your browser. The figure below shows how this works in FireFox:
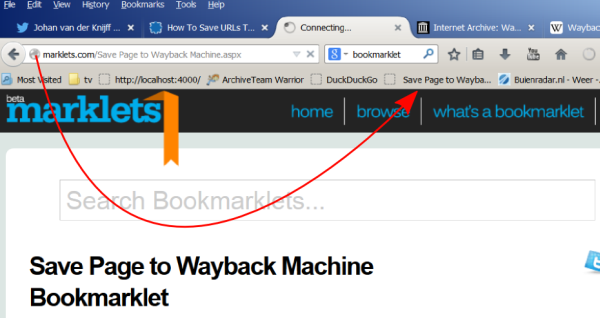
Alternatively you can also use Add Bookmark in the Bookmarks menu.
Using the bookmarklet
- Open the web page that you want to save in your browser.
- Click on Save Page to Wayback Machine in the bookmarks toolbar.
- Wait while the page is being crawled. Once the archiving process is complete, the URL of the archived page appears.
Method 3: Chrome extension
If you’re using the Google Chrome browser, you may want to check out Jimmy Lin’s “Save a Page” extension. Once installed, it allows you to save a page by simply right-clicking on it. The extension can be found here:
https://github.com/lintool/chrome-archive-this-page
Just follow the installation instructions on that page.
Limitations
- Webmasters can use robots.txt to prevent web crawlers from crawling/saving anything on their website.
- If a webmaster decides to change the robots.txt permissions at some point in the future, a saved page may be removed from the Wayback Machine. For details see: https://archive.org/about/exclude.php.
Acknowledgement
This tutorial partially draws from a blog post by Gary Price on Search Engine Land.
-
web-archiving
- How to preserve your personal Twitter archive
- Mapping the Dutch web domain
- Restoring Liesbet's Virtual Home, a digital treasure from the early Dutch web
- Web domain geolocation and spatial analysis with QGIS
- Crawling offline web content: the NL-menu case
- Resurrecting the first Dutch web index: NL-menu revisited
- Dutch newspaper wipes out articles citing fabricated sources - Internet Archive to the rescue!
- Perdiep Ramesar in het Internet Archive
- Demise of the Dutch Blogosphere
- How to save a web page to the Internet Archive

Comments
This Python based CLI works very well, very convenient for scripting and quick saving and archiving in general
https://github.com/palewire/savepagenow
Installation:
pip install savepagenowUsage:savepagenow URL