
Jpylyzer 2015 round-up
Yesterday (7 December) we released version 1.16.0 of the jpylyzer tool, which is this year’s third release of the software (excluding bugfix releases). This blog post gives a brief overview of the main jpylyzer improvements that have been implemented over this year.
Changes in XML output
The 1.14 release introduced two output improvements. Most importantly, an XML Schema Definition (XSD) was created. The schema formally defines the output format, and it also makes it possible to validate output files. In addition, a namespace declaration was added. These changes make the post-processing of jpylyzer’s output more straightforward.
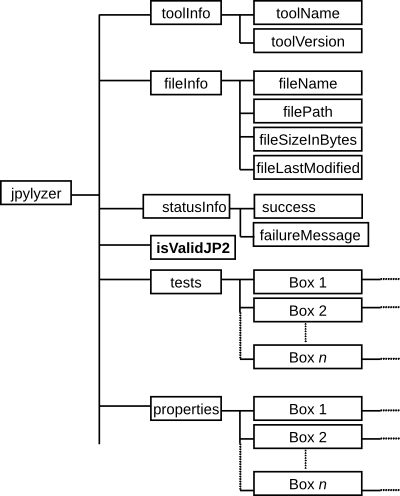
The 1.16 release added the statusInfo element, which tells you whether the validation completed without any internal errors. It contains the following sub-elements:
-
success: a Boolean flag that indicates whether the validation attempt completed normally (“True”) or not (“False”). A value of “False” indicates an internal error that prevented jpylyzer from validating the file.
-
failureMessage: if the validation attempt failed (value of success equals “False”), this field gives further details about the reason of the failure.
This means that the general structure of the output now looks like this:
Recursive traversal of directory trees
Another feature that was introduced with the 1.14 release is the --recurse option. This allows one to recursively traverse a directory tree. The code for this feature was created by Adam Retter, Jaishree Davey and Laura Damian of The National Archives (UK).
Memory mapping
The 1.15 release introduced the use of memory mapping for reading input images. This results in better performance when processing (very) large files. Images that would cause a memory error in previous versions are now handled without any problem. Also, the processing of very large files can be significantly faster than in earlier releases, and is less prone to freezing other processes that are simultaneously running on the machine. This improvement was suggested by Stefan Weil of Mannheim University Library, and the changes are based on a patch he submitted.
Two examples illustrate the benefits of this change:
-
This 2 GB image resulted in a memory error with jpylyzer 1.14.2 on a Windows machine with 4 GB RAM. The latest versions process the file without problems.
-
On a Linux Mint machine with 8 GB RAM, this 6.7 GB image also resulted in a memory error. Again, the current version handles the file without any problem.
This doesn’t mean that memory errors are now a thing of the past entirely; they may still occur under some circumstances. For instance, a test with the 6.7 GB image failed on a Linux Mint machine with 4 GB RAM. So it seems prudent to make sure that the amount of available RAM always exceeds the maximum image size by a fairly wide safety margin. Also, chip architecture and operating system may put further constraints on the amount of memory than can be mapped at a time.
Improved exception handling
Prior to release 1.16.0, an exception during the processing of an image could cause jpylyzer to crash. For example, an extremely large image can result in an internal memory error, and this would grind jpylyzer to a halt. This is particularly problematic when using the new --recurse option: in this case a single jpylyzer invocation may involve the processing of thousands of images at a time. One single (e.g. extremely large) image could then result in unusable output; moreover, it would be difficult to identify which image caused the crash in the first place! Release 1.16.0 introduces improved exception handling that allows jpylyzer to handle such situations more gracefully.
Robustness
The combined effect of the exception handling, memory mapping and status output should make jpylyzer releases from 1.16.0 onwards significantly more robust than previous versions. As an example, here’s some (simplified) output for a 6.5 GB JP2 that caused a memory error:
<?xml version='1.0' encoding='UTF-8'?>
<jpylyzer>
<toolInfo>
<toolName>jpylyzer.py</toolName>
<toolVersion>1.16.0</toolVersion>
</toolInfo>
<fileInfo>
<fileName>AS16-P-4102.jp2</fileName>
<filePath>/home/johan/testJpylyzer/AS16-P-4102.jp2</filePath>
<fileSizeInBytes>6745365021</fileSizeInBytes>
<fileLastModified>Wed Dec 2 20:05:29 2015</fileLastModified>
</fileInfo>
<statusInfo>
<success>False</success>
<failureMessage>memory error (file size too large)</failureMessage>
</statusInfo>
<isValidJP2>False</isValidJP2>
<tests/>
<properties/>
</jpylyzer>
Previous versions would simply crash in this situation. Now, automated workflows can simply check for the value of the success field to verify the status of the validation. More importantly, if the jpylyzer invocation involved multiple input files (e.g. through the --recurse option), errors like these will not stop the processing of the remaining files.
64-bit Windows binaries
Finally, from version 1.15.1 onwards we are now providing 64 bit Windows binaries of jpylyzer (previously only 32-bit binaries were available).
Links
Originally published at the KB Research blog
-
JP2
- Generating lossy access JP2s from lossless preservation masters
- Jpylyzer 2015 round-up
- Response to report on JPEG 2000 expert round table
- Six ways to decode a lossy JP2
- Jpylyzer software finalist voor digitale duurzaamheidsprijs
- Optimising archival JP2s for the derivation of access copies
- ICC profiles and resolution in JP2: update on 2011 D-Lib paper
- Automated assessment of JP2 against a technical profile
- Update on jpylyzer
- Jpylyzer documentation
- A prototype JP2 validator and properties extractor
- A simple JP2 file structure checker
- Paper on JPEG 2000 for preservation
- Ensuring the suitability of JPEG 2000 for preservation
-
jpeg-2000
- Generating lossy access JP2s from lossless preservation masters
- Jpylyzer 2015 round-up
- Response to report on JPEG 2000 expert round table
- Six ways to decode a lossy JP2
- Jpylyzer software finalist voor digitale duurzaamheidsprijs
- Optimising archival JP2s for the derivation of access copies
- ICC profiles and resolution in JP2: update on 2011 D-Lib paper
- Automated assessment of JP2 against a technical profile
- Update on jpylyzer
- Jpylyzer documentation
- A prototype JP2 validator and properties extractor
- A simple JP2 file structure checker
- Paper on JPEG 2000 for preservation
- Ensuring the suitability of JPEG 2000 for preservation
-
jpylyzer
- Generating lossy access JP2s from lossless preservation masters
- Jpylyzer 2015 round-up
- Jpylyzer software finalist voor digitale duurzaamheidsprijs
- Adventures in Debian packaging
- Automated assessment of JP2 against a technical profile
- Update on jpylyzer
- Jpylyzer documentation
- A prototype JP2 validator and properties extractor
- A simple JP2 file structure checker

Comments